Examples¶
Store and forward¶
Preparation¶
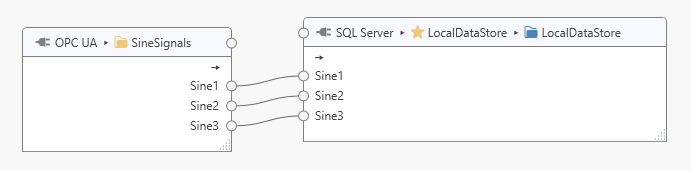
In this example, we would like to store and forward a set of data consisting of three “Sine” signals (Sine1, Sine2, and Sine3) originating from an OPC UA Server. The OPC UA topic is configured to send new data every 5 seconds. We will configure two databases, one local and one remote. The remote database connection is considered less reliable, and outages are expected. Data is therefore collected into the local database first, from where it is transferred to the remote database while the remote database is available.
The local database in this example is a SQL Server database and the remote database is a PostgreSQL database, that means, data is replicated across different database engines. If both database engines were the same (or if otherwise supported), then built-in features for data replication may also be an option. However, the goal here is to demonstrate data replication within Dataristix only.
Local and remote databases are configured to point to the local PostgreSQL database and the remote SQL Server database respectively. We will be using the specific PostgreSQL and SQL Server connectors in this example, however, the ODBC connector may be used instead, for both, the local database and the remote database.
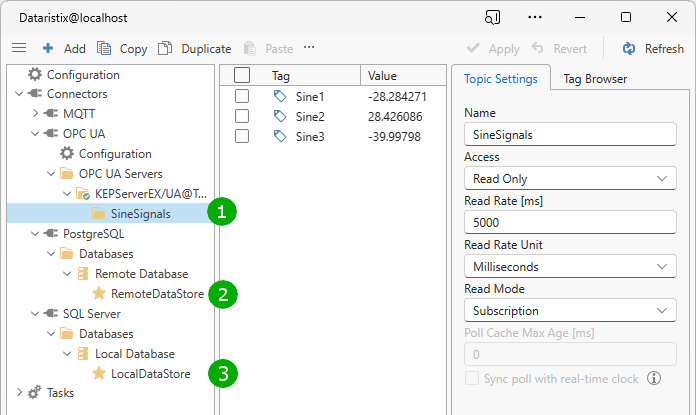
In the image above, we have the configured OPC UA topic “SineSignals” (1), the remote database and writable topic (2) and the local database and writable topic (3). The writable topics are in both cases left at their default configuration with “Create tables and columns automatically” enabled (you may want a topic with specific tags for production use later).
Now we temporarily add the following task to let Dataristix create tables and columns automatically by briefly sampling some data:
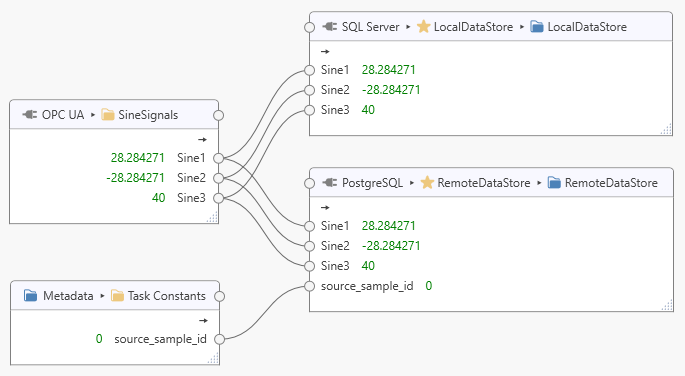
Note that we have added a task constant “source_sample_id” of type “Int32” to create an additional field in the remote database table to hold the local “sample_id”; this will help identify the replicated local dataset later.
Start the task and ensure that data can be stored into the databases successfully, then stop the task again (you can delete the task afterwards if you like).
Note
Dataristix automatically creates an index on the “sample_datetime” field and an auto-incrementing “sample_id” field. If you are planning to create tables manually or plan to use an existing table, then ensure that there is an identity field and that the relevant timestamp field is indexed; performance may suffer otherwise. You can also create a single index on both, the “sample_datetime” and “sample_id” fields.
We should now see that the u_localdatastore and u_remotedatastore database tables contain some data. Running the following “psql” command for the remote database, for example, may yield:
postgres=# select * from u_remotedatastore;
sample_id | sample_datetime | source_sample_id | sine1 | sine2 | sine3
-----------+----------------------------+------------------+-----------+------------+------------
1 | 2023-07-15 23:18:38.427146 | 0 | | |
2 | 2023-07-15 23:18:43.457628 | 0 | 39.999496 | -39.999496 | 0.40211707
You can change the default database table prefix “u_” as in “u_remotedatastore” to blank or a different prefix for future automatically created tables by changing the “Advanced” database settings.
Because we later want to check the source_sample_id for potential duplicates, we also want to create an index for this field to ensure that the lookup performs well. Delete all but one entry in the table so that we can create a unique index:
postgres=# delete from u_remotedatastore where sample_id <> 1;
Then create the unique index:
postgres=# create unique index source_sample_id_idx on u_remotedatastore (source_sample_id);
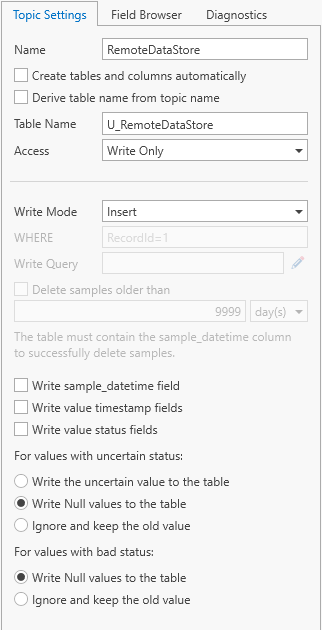
For the remote datastore, we can now untick options “Create tables and columns automatically”, “Derive table name from topic name”, and also “Write sample_datetime field” option since this field will be transferred from the local storage to the remote storage.
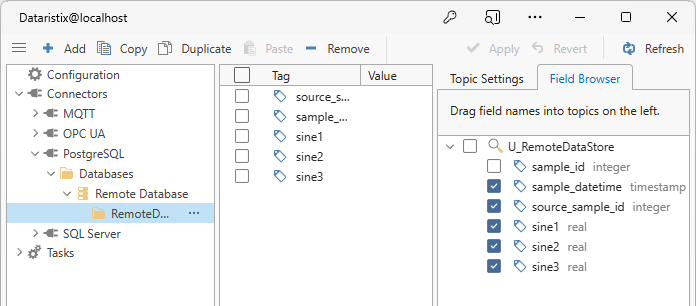
From the field browser, drag fields “sample_datetime”, “source_sample_id”, “sine1”, “sine2”, and “sine3” into the topic.
Option 1, poll for changes¶
If the sampling rate is low so that polling of the remote database is efficient enough to keep the remote database up to date in a timely fashion, then the following approach may be taken.
- Query the latest “sample_datetime” that is stored in the remote database.
- Select the first data set in the local database with a “sample_datetime” that is greater than the latest “sample_datetime” of the remote database.
- If there is such a dataset, then transfer the local dataset to the remote database.
- Repeat
This will keep the remote database up to date as long as the polling interval for the remote database is faster than the sampling rate for new samples arriving in the local database.
Here, the OPC UA “SineSignals” are sampled every 5 seconds. With a polling interval of 1 second, data is transferred to the remote database five times faster than new data arriving in the local database. The transfer will therefore always be able to “catch up” with the new data, provided that the remote database connection is up long enough. Assuming that the remote database connection is lost for one hour (3600 seconds) then the local database would have accumulated 3600/5 = 720 new local samples. It would take 720 seconds or 12 minutes to transfer these samples to the remote database (and some more time for any new samples added in the interim).
Tip
The lower the data source sampling rate (i.e., for the OPC UA “SineSignals”) compared to the acceptable database polling rate, the faster it will be for the remote database be up to date again after outage. If the sampling rate was 5 minutes and the polling interval was 10 seconds (30 times the sampling rate) for example, then, after a one hour outage, the remote database would be up to date again in a about 2 minutes.
Read latest remote timestamp¶
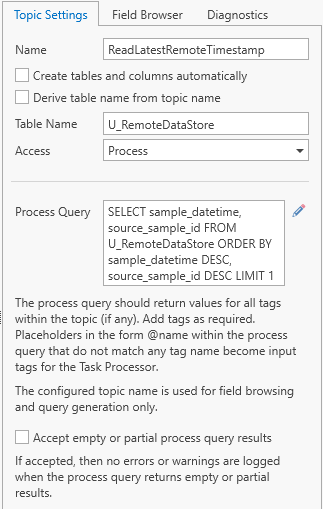
As the first step, we add a topic “ReadLatestRemoteTimestamp” to the remote database to query the latest “sample_datetime” field in the “u_remotedatastore” table. In this example, we configure the topic with “Process” access and a query that selects the maximum timestamp. A “Process” topic will enable us to trigger database queries within the data transfer task and return some result, as we will see later. In the topic settings, untick the “Create tables and columns automatically” and “Derive table name from topic name” options, enter table name “U_RemoteDataStore”, change the “Access” to “Process”. Enter the following process query:
SELECT sample_datetime, source_sample_id
FROM U_RemoteDataStore
ORDER BY sample_datetime DESC, source_sample_id DESC
LIMIT 1
The query selects the latest pair of “sample_datetime” and “source_sample_id” from the remote database.
Note
The above settings assume that the “U_RemoteDataStore” table is pre-populated with at least one record. If this is not the case then consider modifying the query to return a minimum “sample_datetime” and a default “source_sample_id” (i.e., via “COALESCE”).
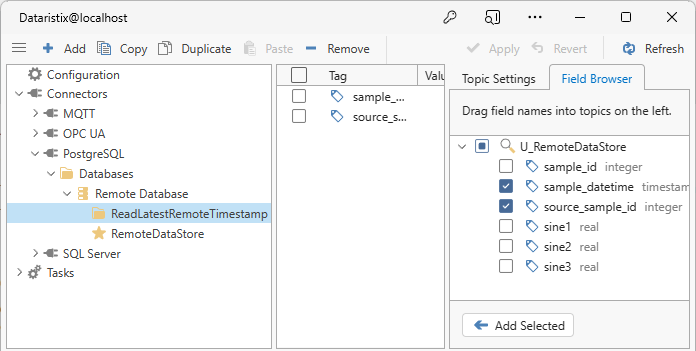
After “Apply”, we can use the Field Browser to drag the “sample_datetime” and “source_sample_id” fields into the topic; these are the fields returned by the query that need a matching tag.
Read newer local timestamp¶
For the local database, we need a topic that allows querying the database for a dataset with a timestamp that is greater than another timestamp (the latest timestamp of the remote database):
SELECT TOP 1 sample_id, sample_datetime, Sine1, Sine2, Sine3
FROM U_LocalDataStore
WHERE sample_datetime > @remoteSampleDateTime AND sample_id > @remoteSourceSampleId
ORDER BY sample_datetime, sample_id
This query selects the first dataset with a “sample_datetime” greater than input parameter “@remoteSampleDateTime”. Comparing the “sample_id” with the “@remoteSourceSampleId” ensures that potential timestamp precision related differences in local and remote databases do not result in the same record being replicated endlessly. The “TOP 1” expression is SQL Server specific (for PostgreSQL you could use “LIMIT 1”).
Create a “ReadNewerLocalTimestamp” topic for the local database, untick the “Create tables and columns automatically” and “Derive table name from topic name” options, enter table name “U_LocalDataStore”, change the “Access” to “Process” and enter the query above as the “Process Query”. Because the query may return empty results, we also check option “Accept empty or partial process query results”.
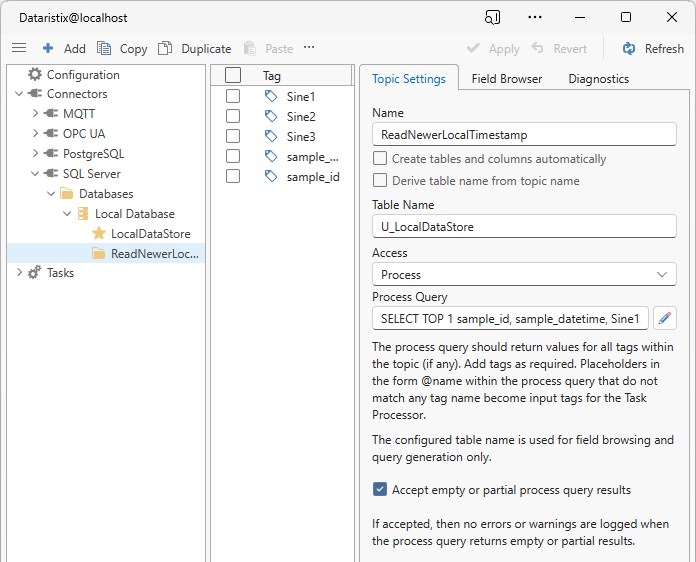
As before, click on “Apply” and use the Field Browser to drag tags into the topic. This time we add tags “sample_id”, “sample_datetime”, “Sine1”, “Sine2” and “Sine3”.
We are now ready to construct tasks that connect the various topics for data transfer.
Local storage task¶
The first task simply stores data into the local database with an update rate as determined by the OPC UA “SineSignals” topic (every 5 seconds in this example):
Polling replication task¶
The second task transfers data from the local database to the remote database:
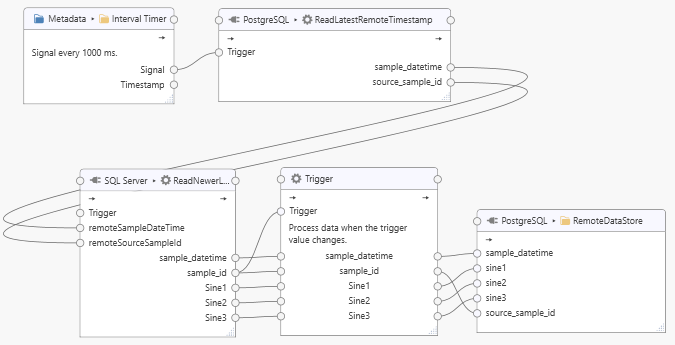
The task uses an interval timer to regularly trigger a query for the latest sample in the remote PostgreSQL database by feeding the “Signal” tag into the “ReadLastestRemoteTimestamp” topic’s “Trigger” tag (the signal value is an always changing counter). The “sample_datetime” and “source_sample_id” returned by the “ReadLatestRemoteTimestamp” process query is sent to the corresponding “remoteSampleDateTime” and “remoteSourceSampleId” tags. We do not need to connect the “Trigger” tag of the “ReadNewerLocalTimestamp” task node. If the “ReadNewerLocalTimestamp” query returns a dataset and a new “sample_id”, then the connected “Trigger” node will forward the dataset to the “RemoteDataStore” (note that we have configured the “Trigger” node to forward data “when the trigger value changes”). The cycle repeats with the next signal triggered by the interval timer. Adjust the interval timing to the slowest acceptable rate.
Option 2, event driven replication¶
In this approach, datasets are replicated as soon as they arrive in the local database. If the remote database connection was down, then local datasets are replicated very quickly when the remote database becomes available again. We use the MQTT connector to signal events across tasks. The general approach is:
- Whenever a new local sample is stored, then send a message to the local MQTT broker as a “LocalDataStoredEvent” MQTT topic.
- Whenever a new remote sample is stored, then send a message to the local MQTT broker as a “RemoteDataStoredEvent” MQTT topic.
- In the replication task, subscribe to both MQTT topics. When a new message arrives then replicate any new local dataset into the remote database and send the “RemoteDataStoredEvent” MQTT message, creating a feedback loop.
Configure MQTT topics¶
To begin, we enable the local MQTT broker and add a “Publish” topic “SineSignalsStoreEventPublisher” with default settings “Quality of Service” set to “At most once” and “Payload Format” set to “Text”. We then manually add the following tags using the “Add” toolbar button:
xfer/sinesignals/latest_remote_sample_key
xfer/sinesignals/initial_remote_sample_key
xfer/sinesignals/latest_local_sample_key
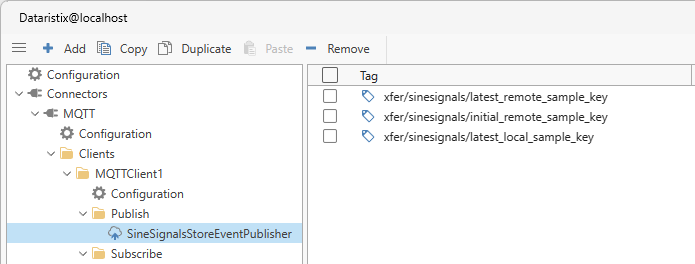
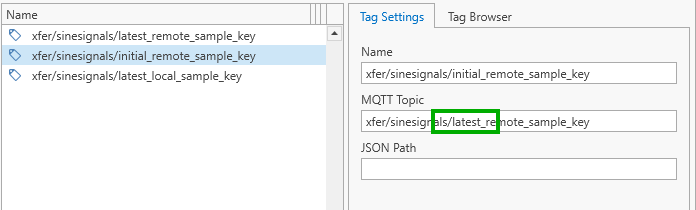
Because we would like to send outputs from two different sources to the same MQTT topic within the same task (as we will later see when we construct the replication task), we change the MQTT target topic for the “xfer/sinesignals/initial_remote_sample_key” tag to also point to MQTT topic “xfer/sinesignals/latest_remote_sample_key”:
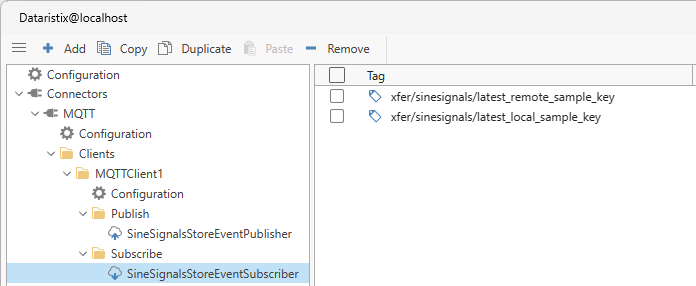
We also add an MQTT client as the subscriber with tags:
xfer/sinesignals/latest_remote_sample_key
xfer/sinesignals/latest_local_sample_key
Because we only want to send a signal to the MQTT broker after successfully storing a new sample, we change the “LocalDataStore” and “RemoteDataStore” topics that we have prepared earlier as follows.
Local storage query¶
For the “LocalDataStore”, untick options “Create tables and columns automatically”, “Derive table name from topic name”, and change the “Access” to “Process”. Enter the following process query:
The query for the “LocalDataStore” is:
INSERT INTO U_LocalDataStore (sample_datetime, Sine1, Sine2, Sine3)
OUTPUT INSERTED.sample_id as sample_id_inserted, INSERTED.sample_datetime as sample_datetime_inserted
VALUES (@sample_datetime, @Sine1, @Sine2, @Sine3)
This query inserts a dataset and returns the inserted “sample_id” and “sample_datetime”.
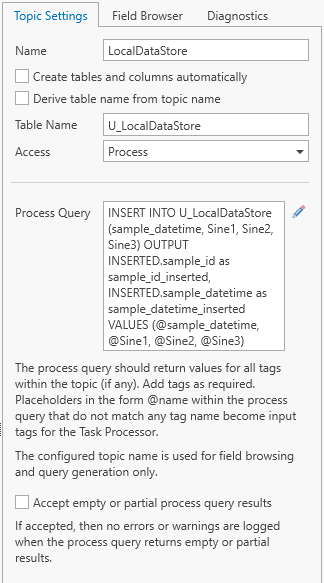
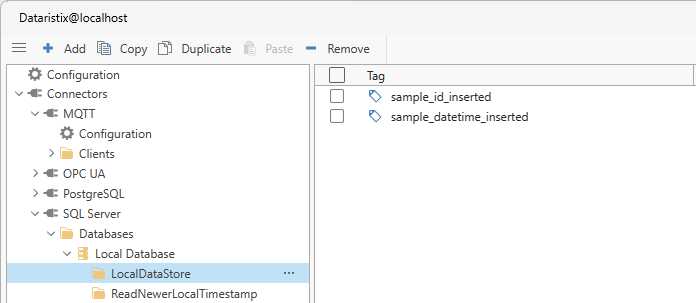
Manually add the “sample_id_inserted” and “sample_datetime_inserted” tags so that we can connect them later.
Note
In this example we are using the Timestamping Processor to generate a timestamp when new data arrives to pass it into the process query. You can also use Value Properties Decoder Processor to obtain timestamps generated at the source of the data, or you can use a database-generated timestamp instead.
Remote storage query¶
The query for the “RemoteDataStore” is:
INSERT INTO U_RemoteDataStore (sample_datetime, source_sample_id, sine1, sine2, sine3)
SELECT @sample_datetime, @source_sample_id, @sine1, @sine2, @sine3
WHERE NOT EXISTS (SELECT * from U_RemoteDataStore WHERE source_sample_id = @source_sample_id)
RETURNING source_sample_id as source_sample_id_inserted, sample_datetime as sample_datetime_inserted
This query inserts a dataset if the dataset does not yet exist and returns the inserted “source_sample_id” and “sample_datetime”. Because the query may return empty results, we check option “Accept empty or partial process query results” to prevent error messages being logged.
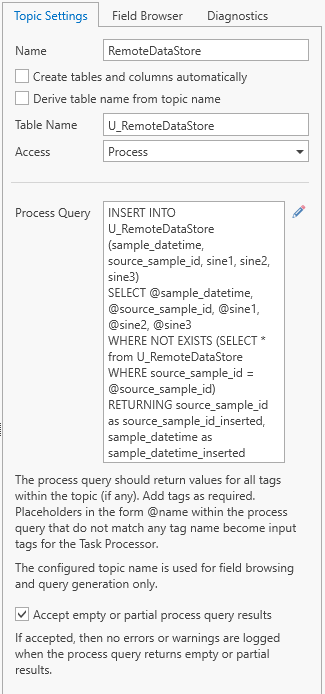
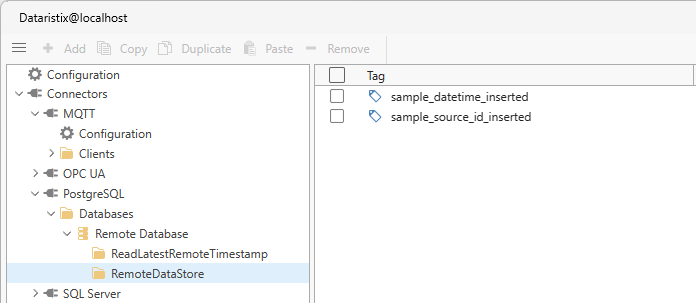
Add the “sample_datetime_inserted” and “sample_source_id_inserted” tags for later use.
Local storage task¶
Next, we can construct the local storage task:
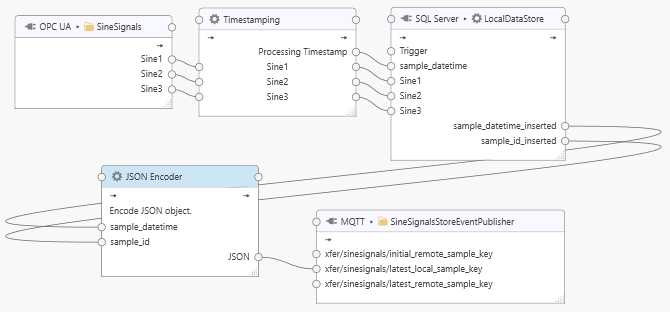
The task receives the “SineSignals” as inputs, timestamps the inputs on arrival, then stores the dataset into the local database. The local database query returns the inserted “sample_datetime_inserted” and “sample_id_inserted” pair which is passed onto the JSON encoder before sending the JSON payload to MQTT topic “xfer/sinesignals/latest_local_sample_key”. The JSON object for encoding the latest local sample key is defined as:
{
"sample_datetime": "",
"sample_id": 1
}
Event driven replication task¶
The remote storage task for replication is constructed as follows:
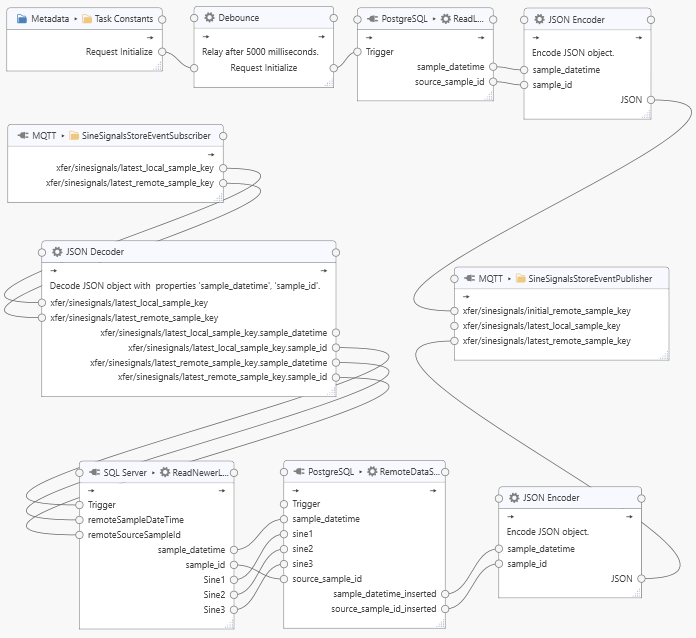
The task consists of two parts, an initialization pipeline and a replication pipeline. The initialization pipeline, beginning with the “Task Constants”, executes once only. The “Request Initialize” constant is simply defined as a boolean True value. After a delay of five seconds (via the “Debounce” Processor), the “ReadLatestRemoteTimestamp” query is triggered to obtain the latest sample key present in the remote database. The delay ensures that the replication pipeline is subscribed to the relevant MQTT events. The result of the query is sent to the “xfer/sinesignals/initial_remote_sample_key” tag which is configured to (also) send a message to the latest remote sample key MQTT topic “xfer/sinesignals/latest_remote_sample_key”. The initialization pipeline must succeed at least once (i.e., when the task is started) for the replication to be begin, because the MQTT topic “xfer/sinesignals/latest_remote_sample_key” must be initialized with a valid value. That means, the task must be started while the remote database is available. Alternatives such as retaining MQTT messages are possible but not considered here.
The replication pipeline begins with the “SineSignalsStoreEventSubscriber” task node, which subscribes to both, the latest local and remote sample keys (the “xfer/sinesignals/latest_local_sample_key” and “xfer/sinesignals/latest_remote_sample_key” MQTT topics). Therefore, storing a local sample or storing a remote sample will both result in a run of the pipeline.
The JSON Decoder decodes the latest local and remote “sample_datetime” and “sample_id” respectively. When there is a change in the latest local “sample_id” or any change in the latest remote “sample_id” or “sample_datetime”, then the `”ReadNewerLocalTimestamp” query is triggered, passing the latest “remoteSampleDateTime” and “remoteSourceSampleId” as parameters. If a newer local dataset is found, then the dataset is passed onto the “RemoteDataStore” task node, which inserts the dataset into the remote database, and, on success, returns the inserted, latest remote “sample_datetime” and “sample_id”. The pair is encoded as JSON and sent to the “xfer/sinesignals/latest_remote_sample_key” MQTT topic, which triggers the replication pipeline again, repeating the cycle. As long as there are new local samples to store, the replication pipeline will process new samples in quick succession.
Extending to additional datasets¶
In the examples above, we have called local and remote storage topics simply “LocalDataStore” and “RemoteDataStore” to receive “SineSignals” datasets. If other datasets should be stored also, then the naming should refer to the data that is being stored, for example, the “LocalDataStore” could be referred to as “LocalSineSignalsDataStore”.
As an exercise, use “Duplicate” on database topics, queries, MQTT topics and tasks created within the examples and then adapt the duplicates to operate on a different dataset.